Substrate Engineering: The Missing Discipline in AI
Powerful inventions don't scale on their own, stable substrates do.
The history of technological scaling is, fundamentally, the history of substrates. Civilizations rarely advance because an isolated invention becomes more powerful; they scale because engineers discover a stable foundation upon which countless downstream innovations can reliably operate. Roads serve as the physical substrate for transport networks; electrical grids act as the power substrate for appliances; TCP/IP functions as the logical substrate for digital communication. The historical pattern is invariant: before any complex system can achieve structural reliability, the environment in which it operates must become entirely predictable.
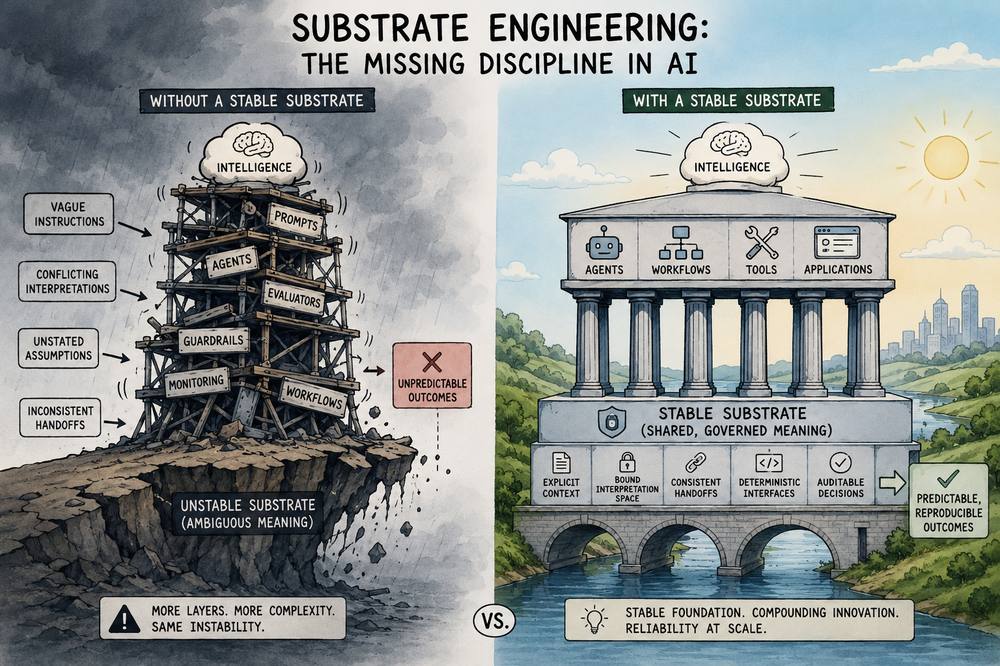
Artificial intelligence is currently colliding with this architectural boundary. The vast majority of contemporary industry effort is concentrated on the most visible tier of the stack: the model layer. Engineering teams spend their cycles cross-referencing benchmarks, evaluating frontier reasoning capabilities, micro-optimizing prompts, and assembling increasingly elaborate agentic workflows. The underlying, unexamined assumption is that systemic reliability will spontaneously emerge as models become incrementally more intelligent.
Yet raw intelligence alone is incapable of creating stability. A highly capable cognitive component operating within an unstable framework remains fundamentally volatile.
This reality becomes starkly apparent when analyzing how enterprise AI deployments actually break. Most production failures are not caused by an absolute deficit of model intelligence. In the vast majority of edge cases, the model fully understands the task description, possesses the required contextual knowledge, and outputs a highly plausible, articulate response. The breakdown occurs because the system lacks structural certainty regarding the exact parameters of the problem it is solving.
A customer communication can support multiple valid logical readings; a legacy document can imply conflicting corporate mandates; a multi-agent workflow can inherit unstated assumptions from an upstream process. When every computational participant interprets a vague instruction reasonably but differently, the macro-system degrades into unpredictability.
The standard engineering response is to treat these interpretive failures as application-level bugs. Teams reflexively stack more guardrails, introduce secondary evaluator models, deploy continuous monitoring tools, and insert supervisor agents into the loop. The architecture grows exponentially more complex, yet the core instability remains unaddressed. This methodology is the engineering equivalent of erecting heavier structures on shifting ground; eventually, the entire development lifecycle becomes entirely dominated by compensatory logic.
Substrate engineering addresses this vulnerability by shifting focus entirely away from individual model outputs and onto the environment in which cognitive decisions occur. Instead of querying whether an isolated model's answer is correct, substrate engineering asks whether the systemic conditions required for reliable execution actually exist. Instead of optimizing semantic output strings, it governs the underlying interpretation space.
The structural divergence between these two approaches is profound. When an operational substrate is unstable, reliability must be continuously, expensively enforced via external monitoring and retroactive correction. When the substrate is architected to be stable, reliability emerges naturally because every computational participant is bounded by identical logical constraints.
The evolution of network computing provides the most precise precedent. TCP/IP did not make individual computers more intelligent, nor did it optimize the internal logic of local applications. It simply established a rigid, predictable substrate for packet data transmission. Once that immutable baseline was secured, entirely new global industries could be confidently engineered on top of it.
An identical paradigm shift is now required for AI. As enterprises transition from single-prompt interfaces to complex networks of interconnected models, databases, and autonomous workflows, the primary engineering hurdle shifts from individual component intelligence to shared semantic coordination.
How does one autonomous system verify that it is solving the exact same problem state as the agent that preceded it? How does an enterprise guarantee that an operational decision maintains absolute coherence across multiple distinct handoffs? How does a workflow remain perfectly reproducible when the underlying model infrastructure is inevitably swapped out?
These are not model questions, nor are they application questions. They are foundational substrate questions that exist beneath the runtime layer, at the exact boundary where digital meaning is formalized.
Over the coming decade, substrate engineering will emerge as a critical, distinct technical discipline. The next generation of enterprise AI infrastructure will not be defined by marginal gains in parameter size or the conversational fluency of autonomous agents. It will be defined by the architectural rigor of the substrates upon which those systems execute.
Intelligence can scale indefinitely, but structural reliability only scales through governed substrates.