Interpretation Drift: The Hidden Failure Mode of AI
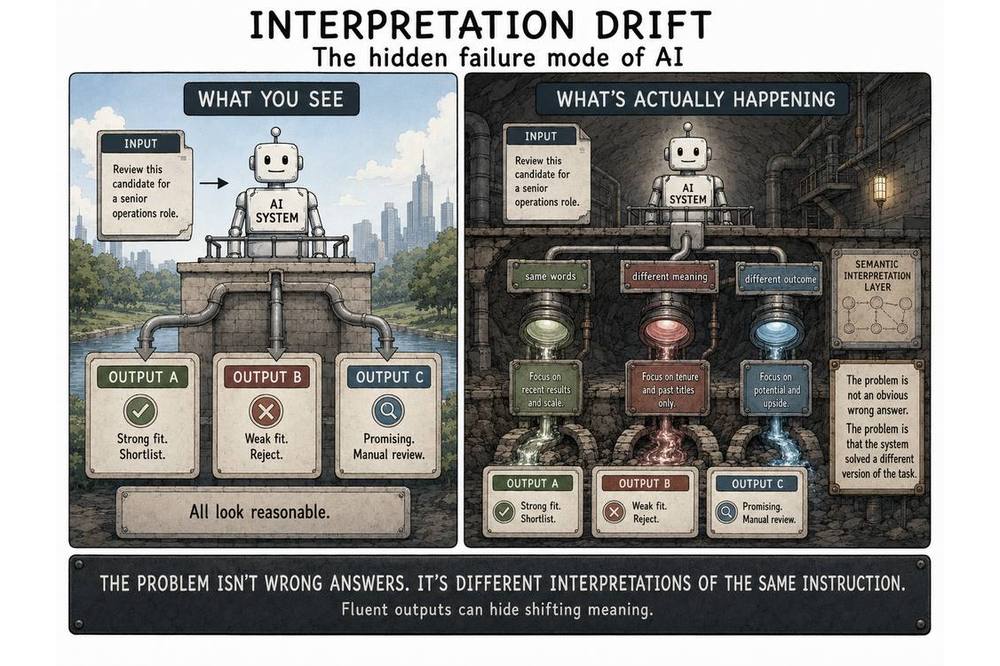
Same input, same model, different conclusion, and none of them obviously wrong.
The AI industry is deeply preoccupied with hallucinations. We talk constantly about models fabricating facts, inventing citations, and confidently delivering wrong answers. Because these failures are conspicuous and easily falsified, they are simple to conceptualize. When a system outputs an objective falsehood, the failure is clear.
Far less attention is paid to a quieter, structural phenomenon that is arguably much more dangerous: the reality that identical inputs can yield entirely different outcomes without any single outcome being obviously incorrect.
If you ask three frontier models to analyze an ambiguous customer complaint, classify a complex legal clause, or evaluate an executive candidate's resume, the resulting assessments will almost always appear highly articulate and reasonable in isolation. Yet under the surface, they frequently diverge. One model flags a risk where another sees an opportunity; one rejects a file that another approves.
Most organizations dismiss this volatility as an immutable tax on probabilistic systems. The industry consensus is that because these models are stochastic, variability is a feature to be managed. Consequently, engineering teams attempt to compensate externally by wrapping models in complex orchestration layers, retry logic, voting mechanisms, and evaluation frameworks.
This approach diagnoses the wrong illness. The core issue isn't that the model generated a different answer; it is that the model solved an entirely different problem.
Human language is highly efficient precisely because it relies on what is left unsaid. People communicate through a massive substrate of shared context, unspoken conventions, and social intuition. We rarely specify every operational constraint because other humans possess the cultural and cognitive machinery to infer our intent.
Large Language Models do not operate this way. When an instruction permits multiple valid logical readings, the model is forced to pick a path. This choice remains invisible to the user because the output is fluent and coherent, hiding the fact that a slight interpretive shift has fundamentally altered the trajectory of the outcome.
This is Interpretation Drift: the phenomenon where the meaning assigned to an instruction shifts while the text of the instruction remains exactly the same.
The consequences of this drift escalate dramatically as AI shifts from content generation to autonomous decision-making. A loose interpretation of a blog post can be edited; a loose interpretation of a credit policy, a candidate screening rule, or a financial transaction executes with immediate, real-world consequences. In these environments, reliability cannot be defined as mere plausibility. True reliability means guaranteeing that every participating system is operating on identical problem parameters.
This challenge compounds as engineering teams adopt multi-agent architectures. Modern enterprise workflows increasingly rely on chains of specialized models, vector databases, and tools passing payloads to one another. Every single handoff introduces a new boundary layer where interpretation can drift. Subtle semantic variations accumulate at each step. A workflow that begins with one clear strategic intention can easily terminate in a materially different, unauthorized outcome.
The standard engineering reflex is to focus on the model itself, assuming that larger parameter sizes, cleaner fine-tuning data, or more elaborate prompting techniques will eventually brute-force the unreliability away.
But this ignores a more elegant possibility: the primary source of system instability may not be a lack of intelligence, but an excess of ambiguity.
If the root cause is ambiguity, then system stability cannot be achieved by optimizing the model's internal weights. It can only be achieved by governing the interpretation space externally. This insight is what drove the architecture of TCP/AP.
Rather than attempting to restrict the fluid intelligence of an LLM, TCP/AP introduces a deterministic protocol layer that binds the interpretation space before execution ever occurs. By forcing independent models to operate within a mathematically bounded set of requirements, the protocol shifts the engineering objective away from the impossible goal of creating deterministic models, focusing instead on delivering reproducible decisions.
Ultimately, reproducibility is what governance, audit, and enterprise compliance actually demand. Organizations do not need conversational fluency; they need systems that behave consistently under fluctuating conditions. Intelligence may generate the underlying options, but structural reproducibility is what determines whether an automated decision can actually be trusted.
The trajectory of AI hardware ensures we will have increasingly intelligent models. Whether we have reliable enterprise systems, however, depends entirely on our ability to govern meaning itself.